TL;DR: Many biological time-series have slow correlation timescales, but default estimators can greatly underestimate these correlations, even if you have enough data to resolve them. Normalizing by a triangle function removes the bias, but at the cost of potentially yielding an “invalid” correlation function estimate.
Science is replete with time-series data, and we’d like to analyze this data to extract meaningful insight about the structure and function of the systems that produce them.
One key set of statistics of a collection of time-series X(t), Y(t), Z(t),… are their auto- and cross-correlation functions, which tell us how strongly values sampled at different time lags covary, and which provide a window into the timescales in the data. Biological time-series in particular often have timescales that are quite slow relative to the durations of our measurements, so it’s important that we estimate these properly and do not miss or misinterpret them.
If you already know what correlation functions are, skip directly to the estimation section.
Auto- and cross-correlation functions
Suppose we have a stationary, univariate random process X(t) ~ P[X(t)], and suppose we know the distribution P[X(t)]. Its autocorrelation function Rx(τ) (sometimes written Rxx(τ)) is defined as
![\[ R_x(\tau) \equiv \textrm{E}[X(t)X(t+\tau)] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-b9c20aae7148198671eb0eaa5c905f2a_l3.png "Rendered by QuickLaTeX.com")
where τ is the time lag between two measurements and E[…] is the expectation over samples X(t). This function Rx(τ) gives the expected product of the signal measured at two different timepoints separated by τ. Stationarity means that Rx(τ) is only a function of τ and not of t.
The autocovariance function Cx(τ) is related to Rx(τ) via
![\[ C_x(\tau) \equiv \textrm{E}[(X(t) - \mu_x)(X(t+\tau) - \mu_x)] = R_x(\tau) - \mu_x^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-854088825739a14aaa12b6ca97d431df_l3.png "Rendered by QuickLaTeX.com")
i.e. it is the autocorrelation function of the signal after its mean µx has been subtracted off. This function Cx(τ) specifies more explicitly how the signal measured at two timepoints separated by τ covary relative to the signal mean µx. For zero-mean signals, however, Cx(τ) = Rx(τ).
A key property of an autocorrelation function in general is that |Rx(τ)| ≤ Rx(0), i.e. the autocorrelation function is bounded by Rx(0). And for a zero-mean signal Rx(0) = Cx(0) is just the variance Var[X(t)], also independent of t.
(Note: the autocovariance Cx(τ) equals to the covariance between x(t) and x(t+τ), but the autocorrelation Rx(τ) does not equal the Pearson correlation R between x(t) and x(t+τ). The Pearson correlation is the covariance scaled by the geometric mean of the variances, which restricts its value to lie between [-1, 1], whereas values of the Rx(τ) have no such restrictions.)
Similarly, the cross-correlation function Rxy(τ) between two signals X(t), Y(t) is given by
![\[ R_{xy}(\tau) \equiv \textrm{E}[X(t)Y(t+\tau)] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-8854bb25f280c1d3f0a9bb9c3557a1e4_l3.png "Rendered by QuickLaTeX.com")
and their cross-covariance function Cxy(τ) by
![\[ C_{xy}(\tau) \equiv \textrm{E}[(X(t) -\mu_x)(Y(t+\tau) - \mu_y)] = R_{xy}(\tau) - \mu_x\mu_y. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-df7f7f565541ad111429b098494ea277_l3.png "Rendered by QuickLaTeX.com")
One of the most important things a correlation function tells us about is the timescales in the signal. The autocorrelation function of white noise, for instance, is zero everywhere except at τ = 0:
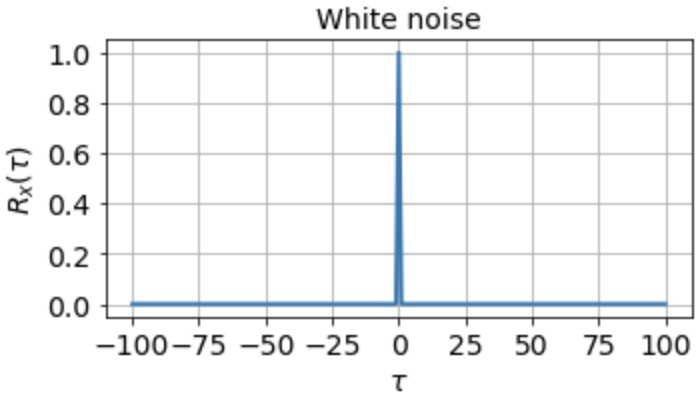
indicating that the signal is completely uncorrelated with itself at any nonzero time lag. For a signal that fluctuates more slowly, however, the autocorrelation function might look something like
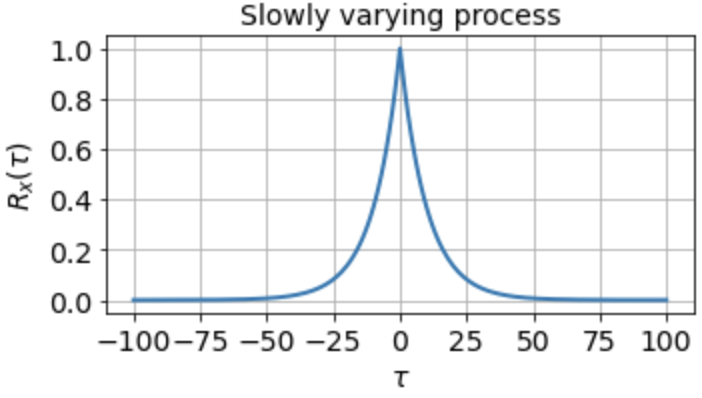
which tells us that the signal is highly correlated with itself at neighboring timepoints and generally up to a timescale of about τ0 ≈ 10 timesteps, but is uncorrelated with itself at any τ ≫ τ0.
If we know the true distribution P[X(t)] or P[X(t), Y(t)], auto- and cross-correlation functions are determined precisely, since they are explicit function(al)s of the known distribution. Oftentimes, however, we do not know the true distribution. Instead we want to estimate these correlation functions from a sample or collection of samples we observe, and which we model as coming from some underlying distribution we wish to understand.
Estimating correlation functions
Suppose for the moment that we have one univariate sample X1*(t) ≡ [x1*(1), x1*(2), …, x1*(T1)], e.g. one sequence X1*(t) of T1 evenly spaced measurement from some recording device. We will assume this comes from some distribution P[X(t)].
Typically when estimating correlation functions one first normalizes the signal by subtracting off an estimate of its mean μx. If we have just one sample, this estimate will be given by
![\[ \hat{\mu}_x = \frac{1}{T_1} \sum_{t=1}^{T_1} x_1^*(t). \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-290e38dfd0b97929fa9a3e0f0708b5b6_l3.png "Rendered by QuickLaTeX.com")
For multiple samples X1*(t), X2*(t), …, Xm*(t), e.g. taken in m different recording sessions, we would use
![\[ \hat{\mu}_x = \frac{1}{\sum_i T_i} \sum_{i=1}^m \sum_{t = 1}^{T_i} x_i^*(t) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-050a089881ef27f1a99cdd25b59a4205_l3.png "Rendered by QuickLaTeX.com")
i.e. the average mean estimate across all the recording sessions, weighted by the session durations.
We can then construct our zero-mean signal
![\[ X_i(t) = X_i^*(t) - \hat{\mu}_x \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-6d3d78f7321c7b8c54ea8164065b02da_l3.png "Rendered by QuickLaTeX.com")
which will be easier to work with, and which we’ll focus on for the rest of the post. We’ll also only focus on the autocorrelation function Rx(τ), although all the same reasoning applies to cross-correlation functions Rxy(τ) as well.
The direct estimator
Given our one sample X1(t), the unbiased estimator for Rx(τ), which is just the covariance (because we removed the mean) between x(t) and x(t + τ), is given by
![\[ \hat{R}_x(\tau) = \frac{1}{N_i-1} \sum_{t=1}^{N_i} x_i(t)x_i(t+\tau) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c835d6d73c33fc8279e4907298df417e_l3.png "Rendered by QuickLaTeX.com")
which is just the usual covariance estimator computed by summing over the product of all Ni (where Ni = Ti – τ – 1) valid pairs (x(t), x(t+τ)) and dividing by Ni – 1.
This we will refer to as the “direct” method, since it directly applies the usual sample covariance formula. (Note that for multiple samples, one collects all valid pairs (x(t), x(t+τ)) across all samples, and divides by Ntotal – 1, where Ntotal = T1 – τ – 1 + T2 – τ – 1 + … .)
The advantages of the direct method are that (1) it gives an unbiased estimate of Rx(τ), and (2) it’s pretty easy to deal with NaNs, since you can just ignore all the (x(t), x(t+τ)) pairs that include a NaN and decrement Ntotal accordingly. A disadvantage, however, is that it is quite slow, since you have to loop explicitly over all τ.
The standard estimator
A faster method, employed all over signal processing is use the estimator
![\[ \hat{R}_x^{st}(\tau) = \frac{1}{T_i - 1} \sum_{t=1}^{T_i-\tau} x_i(t)x_i(t+\tau) = \frac{1}{T_i - 1} x(t) \ast x(-t) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-9acd1286a7b2c5702286b26eabcc6703_l3.png "Rendered by QuickLaTeX.com")
which estimates the correlation function via the convolution of x(t) and x(-t). We’ll call this the standard estimator. The advantage of the standard estimator is that convolutions can be done via the Fast Fourier Transform (FFT), which makes for a much faster algorithm, especially when we have long time-series or high sampling rates.
The key difference between the direct and the standard estimator is that the latter is normalized by Ti-1, which is not a function of τ. This is how SciPy’s scipy.signal.correlate works, along with MATLAB’s xcorr function with default settings. In fact, by default these algorithms don’t even divide by Ti-1, but instead return an “unscaled” version of the covariance function:
![\[ \hat{R}_x^{st}(\tau) = \sum_{t=1}^{T_i-\tau} x_i(t)x_i(t+\tau) = x(t) \ast x(-t). \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-09b2c3a5c669cfcc9e268d1cf1a2beca_l3.png "Rendered by QuickLaTeX.com")
While this is quite fast, as well as quite useful in many applications, the downsides are that (1) it’s hard to deal with NaNs, since this will generally preclude performing a straightforward FFT, and (2) this estimator can introduce a substantial bias, since the normalization is the same for all τ, even though we sum over different numbers of (x(t), x(t+τ)) pairs for different τ.
Unfortunately, the NaN problem is only solved by using the direct method (or via interpolating first, but that’s another story), but we can solve the bias problem quite simply.
The “triangle” estimator
To remove the bias from the standard estimator, we can just divide the result of the standard estimator by a normalization function that does depend on τ, so as to match the direct estimator. In other words, we can use the estimator
![\[ \hat{R}_x^{tri}(\tau) = \frac{\hat{R}_x^{st}(\tau)}{T_i - |\tau| - 1} = \frac{x(t) \ast x(-t)}{T_i - |\tau| - 1} . \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-244968c3ea578d42a2612e6fa427958b_l3.png "Rendered by QuickLaTeX.com")
which we’ll call the triangle estimator since the normalization Ni(τ) = Ti – |τ| – 1 is a triangular function of τ, and provides an unbiased estimate of Rx(τ) since it correctly accounts for the different number of terms in the sum for different time lags τ.
Therefore, if you want an unbiased correlation function estimate from a sample time-series, use the triangle estimator. (Note: you’ll have to do this yourself in Python, or specify “unbiased” as the “scaleopt” argument of MATLAB’s xcorr).
Why the default estimator is biased
It may seem strange that signal processing packages use a biased estimator by default, when the unbiased one is so easy to compute. So why is the biased one the standard?
First, if your recording time far exceeds the timescales you expect in your signal, it doesn’t really make a difference. For instance, if Xi(t) were a 10 kHz, 100-second recording of a noise-driven RC circuit with a time constant τRC somewhere in the range of 1-10 ms, then we would have that
![\[ \frac{N_i(0 ms)}{N_i(100 ms)} = \frac{100 s - 0 ms - .1 ms}{100 s - 10 ms - .1 ms} = \frac{99.999 s}{99.989 s} \approx 1 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-6f65be06e0949233e462baaef3c130f7_l3.png "Rendered by QuickLaTeX.com")
i.e. the normalization factor in the whole range from 0-100 ms (which should be plenty to estimate a 10 ms time constant) barely changes at all, due to the long recording time. Cases like this are common in signal processing, and so even though the estimator is a bit biased, if your recording time greatly exceeds the timescales you expect in the signal, it really doesn’t make much difference.
Second, and a bit more fundamental, is that the correlation function estimated via the unbiased triangle estimator can end up being an invalid correlation function. In particular, one can end up with an estimate where
![\[ \hat{R}_x^{tri}(0) < \hat{R}_x^{tri}(\tau) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c3daee16ecf2e8b1fcaff52c53dc266d_l3.png "Rendered by QuickLaTeX.com")
for some τ ≠ 0, which breaks the important property that Rx(0) ≥ |Rx(τ)| for all τ. This shouldn’t be too surprising, since when normalizing at τ = 0 we divide by a very large number and when normalizing at very large τ we divide by a much small number, which can drastically amplify small fluctuations in the estimator.
Depending on what you’re trying to do, this may or may not be a problem. Having an invalid correlation function, however, can greatly interfere with prediction or sampling, i.e. you could not use an invalid correlation function to specify a valid random process P[X(t)]. Since these are common use cases in signal processing, often a valid yet biased correlation function estimate is preferred over an unbiased but invalid estimate.
A realistic case where this makes a difference
It follows that the biased estimator really only causes problems when the correlation timescales in the data are on the same order as the sample duration. Now, you might be thinking that if we’re in that regime we have no hope of estimating correlations at those timescales in the first place, since we simply don’t have enough data. While the triangle estimate of Rx(400) from a 500 timestep sample may be unbiased, it will have huge variance, since if the signal really is significantly correlated over 400 timesteps, then the 99 timesteps available to the estimator at τ=400 will be far from i.i.d., so we’ll have too few effective independent samples for anything useful anyway.
While that is perfectly sensible, one case where this matters is when we have a large number of short samples of our data. In fact, this is quite common in biology, e.g. if we have data across many short experimental “trials”, if we’re computing behavioral correlations from video data with frequent occlusion periods, if we’re studying brain activity conditioned on a specific brief behavioral states, etc.
To be concrete, let’s see how this all plays out in the following scenario. Suppose we have a single ground-truth signal X(t) of T = 500K timesteps, with an intrinsic timescale of about 300 timesteps (constructed here by smoothing white noise with a 300-timestep squared exponential filter):
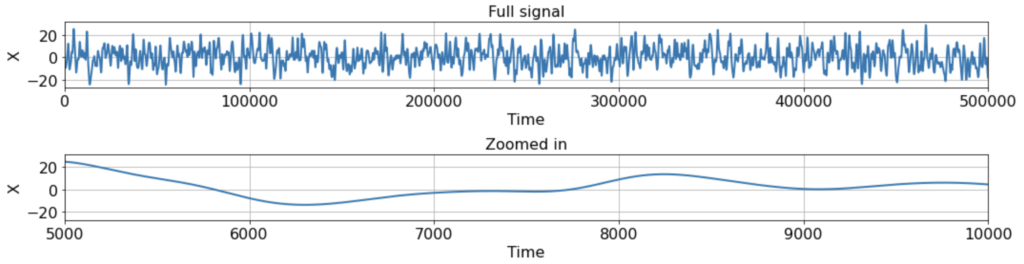
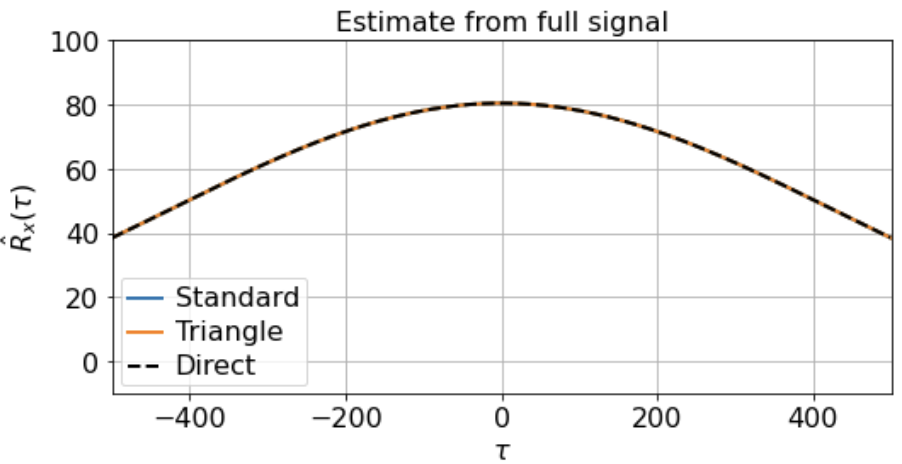
As you can see, the signal is smooth when we zoom in far enough, hence far from i.i.d. close up. Suppose, however, that we’re lucky enough to measure the full signal across all 500K timesteps, and we estimate the correlation function from -500 < τ < 500 using either the direct, standard, or triangle estimators. In this case, the estimator we use does not really matter, as the estimates are extremely similar:
Suppose, however, that we only observe X(t) for 500 timesteps at a time, and that these 500-timestep fragments are randomly distributed throughout the full signal. For instance, maybe we’re interested some slow metabolic process only when the animal is awake, but the animal is only awake for 500 timesteps at a time. Or we’re interested in some state-dependent neural computation, but the state of interest only occurs in about 500-timestep windows.
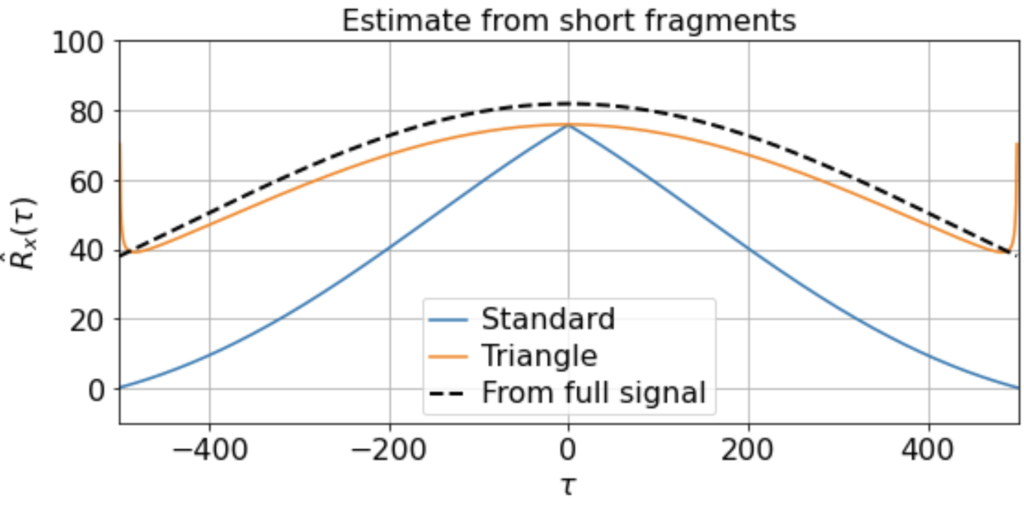
As usual, we first estimate the mean μx across all samples. We then use this to estimate the correlation function Rx(τ) from each 500-timestep sample. Using our three different methods produces something like:
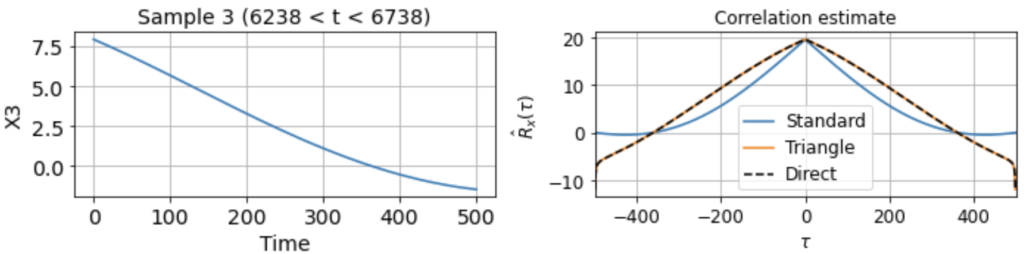
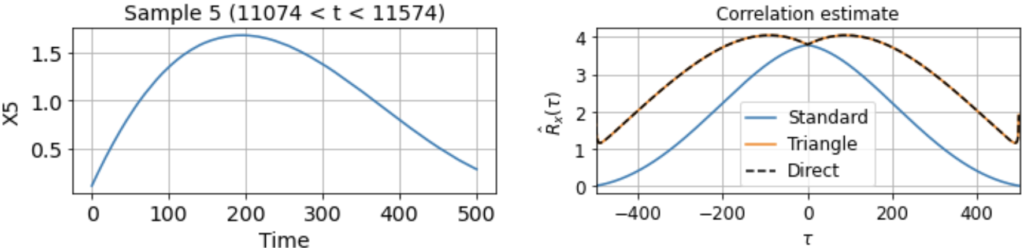
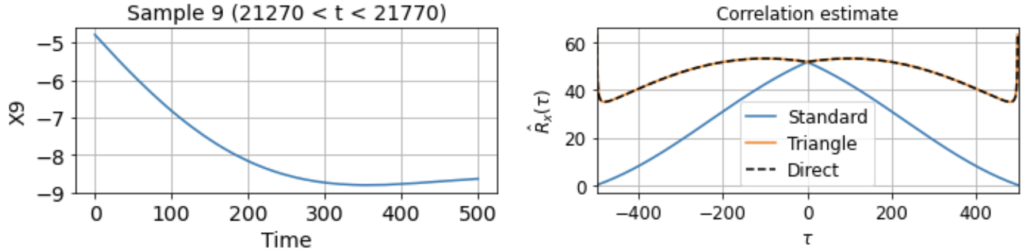
Now we see clearly that the estimates differ rather wildly both across individual samples (since each sample contains only a small, nonrepresentative part of the full signal), as well as between the standard and triangle estimators (and only the triangle estimator matches the direct estimator).
Notably, for τ near 500, the standard estimator estimates Rx(τ) ≈ 0 for all samples, even though we know Rx(500) should be around 40 (see the estimate from full signal above). On the other hand, the standard biased estimator has very low variance around τ near 500, whereas the triangle estimate, while unbiased, is kind of all over the place for Rx(τ ≈ 500). Moreover, we can see in the sample X5 that the estimated correlation function is in fact an invalid correlation function, since Rx(100) > Rx(0). Thus, if you wanted to use an unbiased estimate of the correlation function for sampling purposes, you would run into trouble.
Nonetheless, if we have sufficiently many samples, even if they are of short duration, we can still construct a good estimate by averaging the estimated correlation functions over the samples:
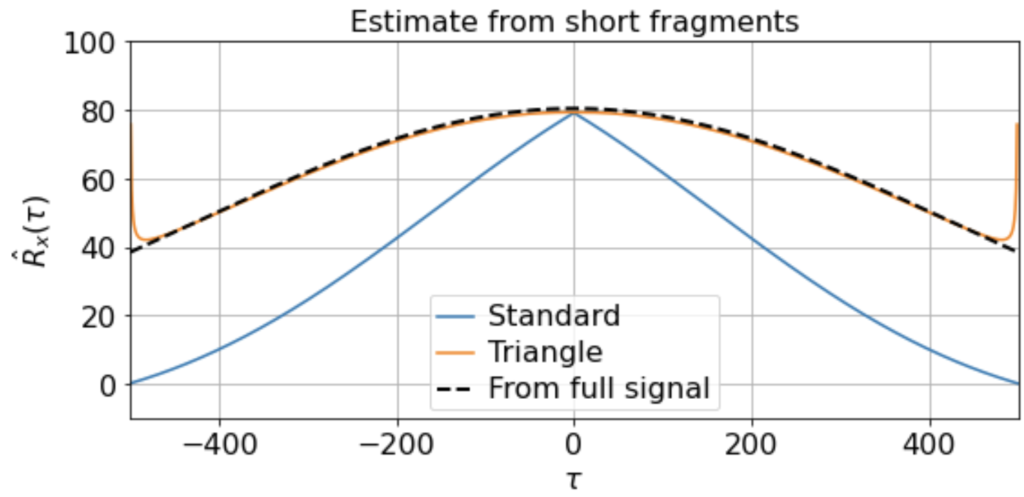
Here we find that the triangle estimator does a much better job at capturing the nonzero slow correlations present in the signal and matches the direct estimate from the full signal much better than does the standard estimator. (Although note that there is still fairly high variance at the edges, since Ni is so small.)
There will be variation, of course, in the averaged triangle estimate across different renditions of this “experiment”. E.g. running it a few times (for 200 x 500-timestep windows taken from a 500K timestep signal) we get
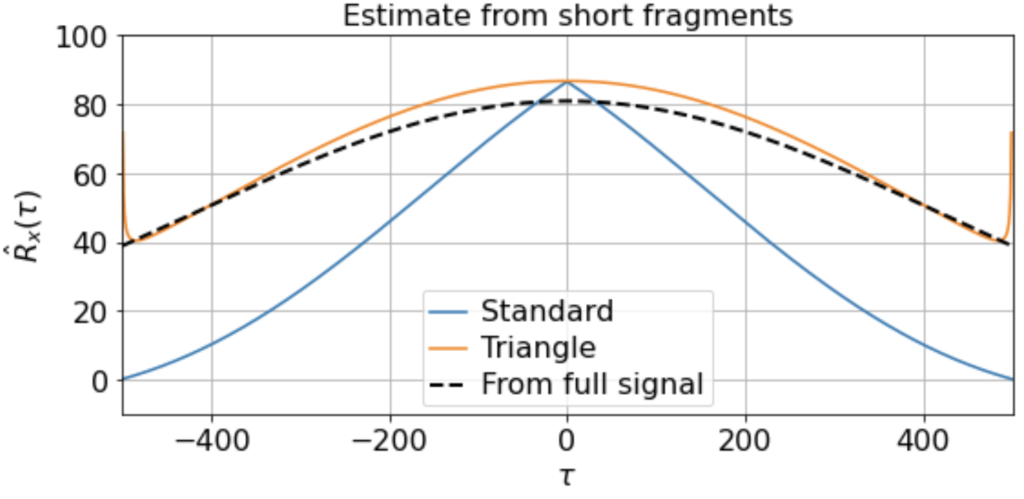
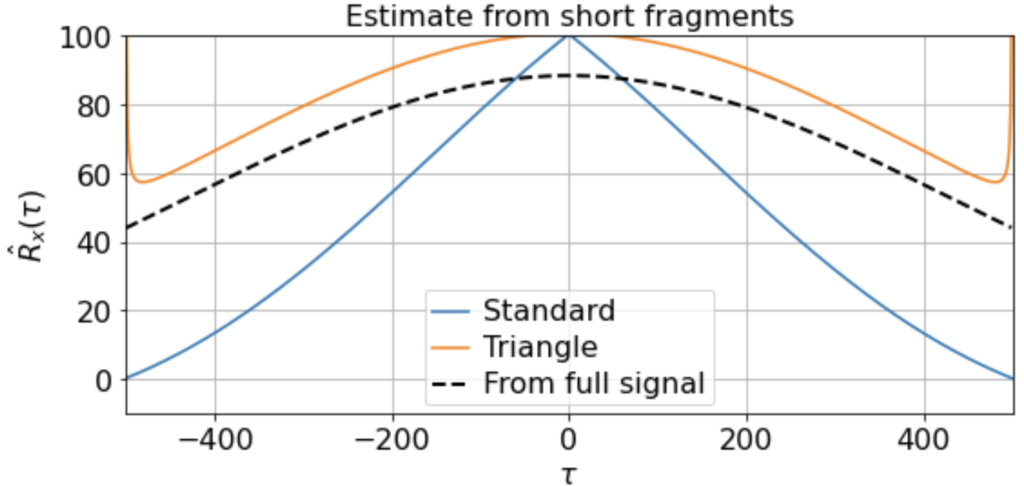
etc. But in all cases the triangle estimator provides a far better match to the correlation function estimated from the full signal, whereas the standard estimator systematically underestimates the slow correlations.
Time-series analysis is a crucial part of science. The life sciences in particular are full of slow proceses, and when analyzing data it is important to understand how the details of your analyses affect your results and interpretations. Overall, I hope that this post has helped clarify how different correlation function estimators operate, and how they can hide or reveal interesting features of your data in different circumstances.
You can view or download the Jupyter notebook accompanying this post here.
Happy sciencing.
![\[y = x_1 + x_2 + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-01021efc85e98e3ba6e8e1f8a70e5c37_l3.png "Rendered by QuickLaTeX.com")
![\[y = \mathbf{w}^T \mathbf{x} + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-25791c89d13bd4eb75220f15e8863014_l3.png "Rendered by QuickLaTeX.com")
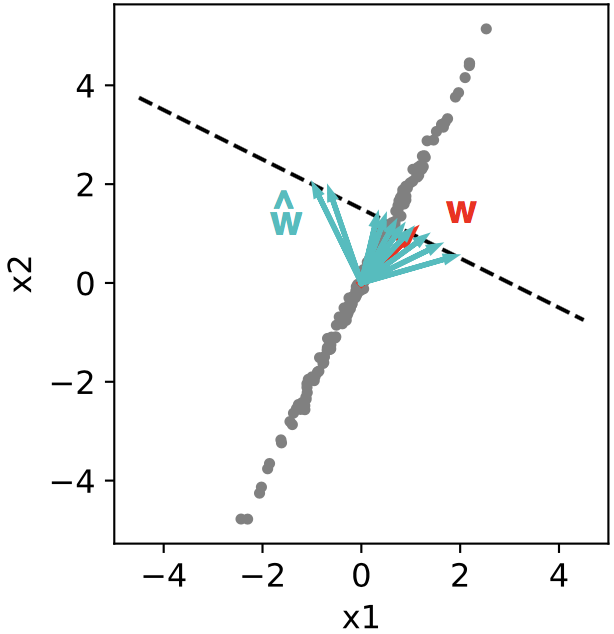
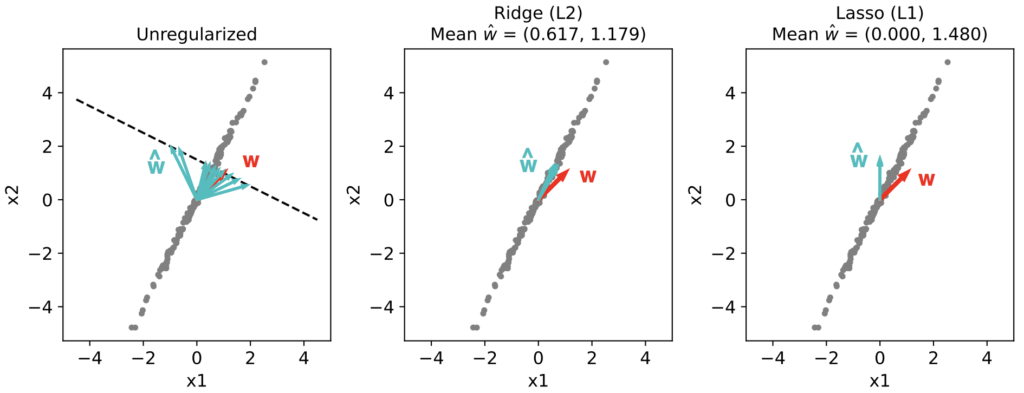
![\[ x_2 = 2x_1 + \eta_x \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-b650927121fc4a99cb88303ecfedf6f8_l3.png "Rendered by QuickLaTeX.com")
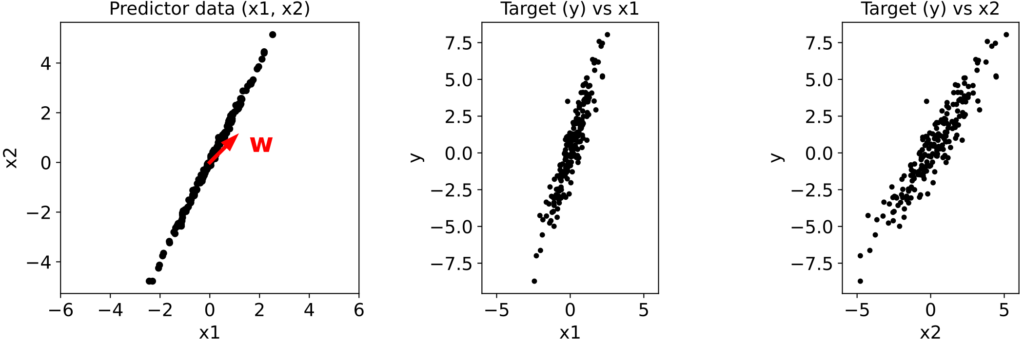
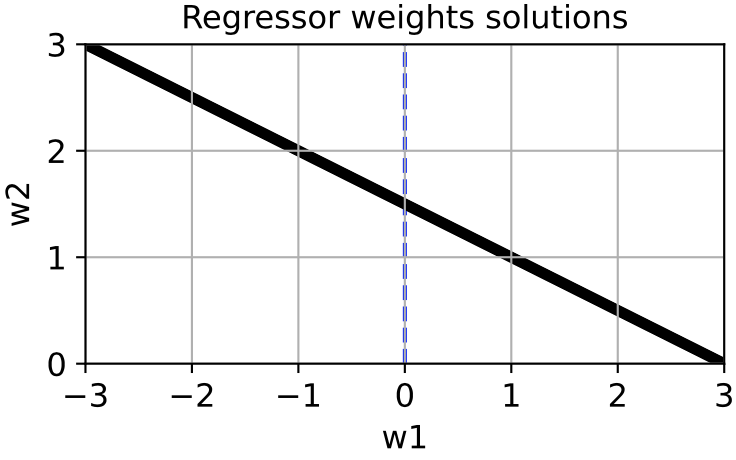
![\[ x_2 \approx 2x_1, \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-5acdb351cf550d1c6402914256e32cae_l3.png "Rendered by QuickLaTeX.com")
![\[ y = x_1 + x_2 + \eta_y \approx 3x_1 + \eta_y \approx 1.5x_2 + \eta_y \approx 5x_1 - x_2 + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-ace735983164449edd48dd09e0535072_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a62adc9c3a168552e61a4144b5910918_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{y}_i = w_1x_1 + w_2x_2 + ... \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a63e0626ed94149ee89784b11a66ec91_l3.png "Rendered by QuickLaTeX.com")
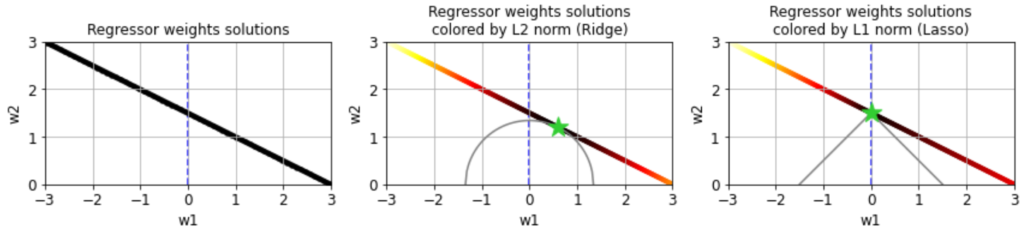
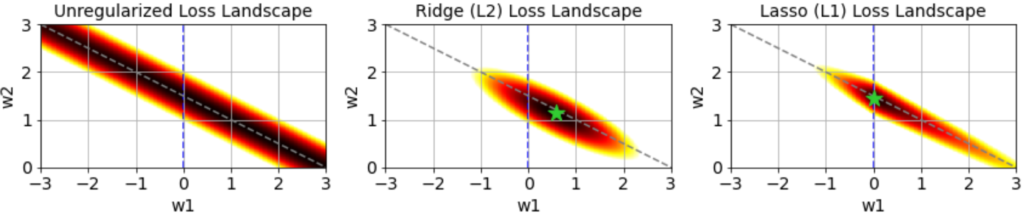
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 + \alpha \lVert \mathbf{w} \rVert_2^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a689eb87a603c782d504e0b361a4ad1e_l3.png "Rendered by QuickLaTeX.com")
![\[\lVert \mathbf{w} \rVert_2 = \sqrt{w_1^2 + w_2^2 + w_3^2 + ...} .\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-05731c7d203f3f4c69989828204b5ad7_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 + \alpha \lVert \mathbf{w} \rVert_1 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-2412607b301febdfccd17399102fa49b_l3.png "Rendered by QuickLaTeX.com")
![\[ \lVert \mathbf{w} \rVert_1 = |w_1| + |w_2| + ... \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c92d458a9879a5865eef8ac2bf8a4d58_l3.png "Rendered by QuickLaTeX.com")
![\[ y(t) = x(t) \ast h(t) + \eta_y(t) . \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-f174eb7f3e420efdd764cb4968df720e_l3.png "Rendered by QuickLaTeX.com")