TL;DR: Shannon’s entropy formula is usually justified by showing it satisfies key mathematical criteria, or by computing how much space is needed to encode a variable. But one can also construct Shannon’s formula starting purely from the simpler notion of entropy as a (logarithm of a) count—of how many different ways a distribution could have emerged from a sequence of samples.
Entropy of a probability distribution
The underpinning of information theory is Shannon’s formula for the entropy H of a discrete probability distribution P. Derived in 1948 in the paper “A mathematical theory of communication”, this is given by
where the pi = p(xi) is the probability of sampling xi from P.
There are many ways to think about entropy, but one intuition is that H quantifies how spread out P is. It is a more general statistic than e.g. variance, because entropy does not require a notion of distance between different xi. Thus one can compute the entropy of a distribution over colors, names, categories, etc., for which variance might not make sense.
For a uniform distribution over N outcomes, the Shannon entropy is:
The entropy is just the number of possible outcomes, counted in log units. Log units are used because the number of outcomes often grows exponentially with system size. For instance, the number of unique binary words of length T is 2T. The entropy of a uniform distribution over such words is therefore log 2T = T bits.
But Eq. 1 applies to all discrete distributions, not just uniform ones. At first glance the general formula is not particularly intuitive. Why the minus sign? Why a probability times a logarithm of a probability? Where does Eq. 1 come from?
Shannon’s derivation
The usual explanation of why Eq. 1 is the right formula for entropy can be found in Shannon’s paper itself (p. 10-11).
Essentially Eq. 1 is the unique solution (up to a positive multiplicative factor) satisfying three criteria: (1) H is continuous in the probability levels, (2) H of a uniform distribution increases with the number of possible outcomes, and (3) if an observation from P can be broken into two or more sequential observations (e.g. first observing whether a sample is in category A or B, then observing its exact value), then H should be decomposable into a weighted sum of the individual entropies.
Appendix 2 of Shannon’s paper shows why Eq. 1 satisfies these, and the proof is quite accessible. However, the derivation essentially starts by assuming one already knows the answer, obscuring how one would have discovered Eq. 1 in the first place.
Expected space required to encode a sample
A second derivation of Shannon’s formula comes from computing the expected number of bits required to encode a sample from P. For instance, if P is a uniform distribution over 4 possible outcomes, it takes log2(4) = 2 bits to encode one of these outcomes (00, 01, 10, or 11), i.e. to communicate to someone else which outcome occurred. More generally, it takes log 1/pi = -log pibits to encode a sample that occurs with probability pi, and the expectation of this quantity is E[-log pi] which is equivalent to Eq. 1.
This derivation is elegant and intuitive, but it requires introducing the notion of encoding. And even though it kind of makes sense that rarer outcomes would require more space to encode, it takes a bit of head-scratching (at least for me) to arrive at why log 1/pi is the right quantity for a non-uniform distribution. (Of course, the link between entropy and encoding is a core element of Information Theory, so it’s definitely worth working through this, but it takes a bit of thinking.)
An alternative construction
Is there a way to arrive at Shannon’s formula without knowing what it should look like ahead of time? And without the notion of encoding? In particular, can we go from the simpler notion of entropy as the log number of possible outcomes of something to Shannon’s formula for an arbitrary P?
It turns out Shannon entropy emerges when we choose that something to be a sequence of samples consistent with a histogram approximating P (i.e. that converges to P in the limit of infinite samples). If we count these in log units, Eq. 1 emerges.
I first saw this derivation in Leonard Susskind’s excellent Statistical Mechanics course (Lecture 3), albeit in a different context—connecting Boltzmann and Gibbs entropy. Below I’ll present it differently, but the math is the same. This derivation is longer than Shannon’s, but it shows how one might have come upon Eq. 1 without already knowing what it should look like and without introducing the notion of encoding.
Entropy as a log count of sequences of samples
Consider drawing L samples from a distribution P, one after another. As L increases, the histogram constructed from the samples will tend toward P. How many different sequences of L samples could have produced a given histogram?
Suppose P is defined over N possible outcomes, x1 , …, xN , and we have collected L1 observations of x1, L2 observations of x2, etc, where L = L1 + … + LN. The number of ways (call this Nseq) we could have gotten L1 samples of x1, L2 samples of x2, etc. is
where we have canceled the second term in each denominator with the next numerator.
Counting in log units we then find that
the log number of different sequences of L samples that would have produced our histogram. Next, letting L be large enough to use Stirling’s approximation (log L! ≈ L log L – L), we find
Regrouping terms,
since L = L1 + … + LN. Factoring out L we have
where we have used
Thus
Since our histogram approaches P as L → ∞ we arrive at
Finally, to obtain a quantity that does not depend on the number of samples we divide both sides by L:
Thus, when we count how many different sequences of samples could have produced P, in log units and normalizing by the number of samples, we arrive once again at Eq. 1. That is, Shannon’s formula is a normalized log-count of how many ways a distribution could have emerged.
TL;DR: Many biological time-series have slow correlation timescales, but default estimators can greatlyunderestimate these correlations, even if you have enough data to resolve them. Normalizing by a triangle function removes the bias, but at the cost of potentially yielding an “invalid” correlation function estimate.
Science is replete with time-series data, and we’d like to analyze this data to extract meaningful insight about the structure and function of the systems that produce them.
One key set of statistics of a collection of time-series X(t), Y(t), Z(t),… are their auto- and cross-correlation functions, which tell us how strongly values sampled at different time lags covary, and which provide a window into the timescales in the data. Biological time-series in particular often have timescales that are quite slow relative to the durations of our measurements, so it’s important that we estimate these properly and do not miss or misinterpret them.
Suppose we have a stationary, univariate random process X(t) ~ P[X(t)], and suppose we know the distribution P[X(t)]. Its autocorrelation function Rx(τ) (sometimes written Rxx(τ)) is defined as
where τ is the time lag between two measurements and E[…] is the expectation over samples X(t). This function Rx(τ) gives the expected product of the signal measured at two different timepoints separated by τ. Stationarity means that Rx(τ) is only a function of τ and not of t.
The autocovariance function Cx(τ) is related to Rx(τ) via
i.e. it is the autocorrelation function of the signal after its mean µx has been subtracted off. This function Cx(τ) specifies more explicitly how the signal measured at two timepoints separated by τ covary relative to the signal mean µx. For zero-mean signals, however, Cx(τ) = Rx(τ).
A key property of an autocorrelation function in general is that |Rx(τ)| ≤ Rx(0), i.e. the autocorrelation function is bounded by Rx(0). And for a zero-mean signal Rx(0) = Cx(0) is just the variance Var[X(t)], also independent of t.
(Note: the autocovariance Cx(τ) equals to the covariance between x(t) and x(t+τ), but the autocorrelation Rx(τ) does not equal the Pearson correlation R between x(t) and x(t+τ). The Pearson correlation is the covariance scaled by the geometric mean of the variances, which restricts its value to lie between [-1, 1], whereas values of the Rx(τ) have no such restrictions.)
Similarly, the cross-correlation function Rxy(τ) between two signals X(t), Y(t) is given by
and their cross-covariance function Cxy(τ) by
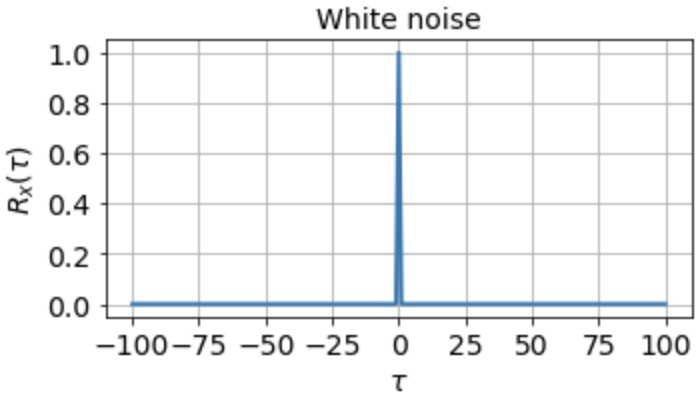
One of the most important things a correlation function tells us about is the timescales in the signal. The autocorrelation function of white noise, for instance, is zero everywhere except at τ = 0:
indicating that the signal is completely uncorrelated with itself at any nonzero time lag. For a signal that fluctuates more slowly, however, the autocorrelation function might look something like
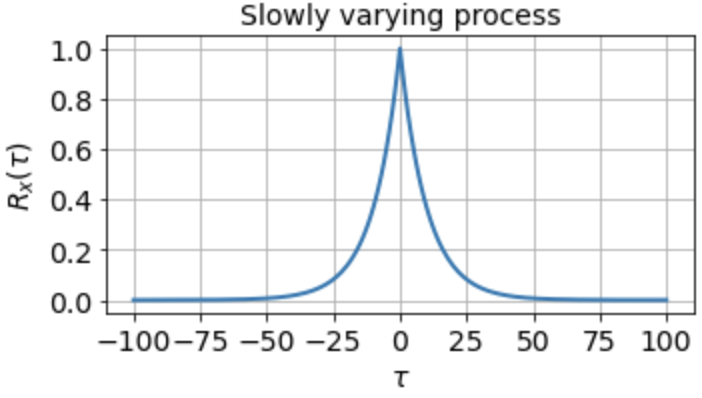
which tells us that the signal is highly correlated with itself at neighboring timepoints and generally up to a timescale of about τ0 ≈ 10 timesteps, but is uncorrelated with itself at any τ ≫ τ0.
If we know the true distribution P[X(t)] or P[X(t), Y(t)], auto- and cross-correlation functions are determined precisely, since they are explicit function(al)s of the known distribution. Oftentimes, however, we do not know the true distribution. Instead we want to estimate these correlation functions from a sample or collection of samples we observe, and which we model as coming from some underlying distribution we wish to understand.
Estimating correlation functions
Suppose for the moment that we have one univariate sample X1*(t) ≡ [x1*(1), x1*(2), …, x1*(T1)], e.g. one sequence X1*(t) of T1 evenly spaced measurement from some recording device. We will assume this comes from some distribution P[X(t)].
Typically when estimating correlation functions one first normalizes the signal by subtracting off an estimate of its mean μx. If we have just one sample, this estimate will be given by
For multiple samples X1*(t), X2*(t), …, Xm*(t), e.g. taken in m different recording sessions, we would use
i.e. the average mean estimate across all the recording sessions, weighted by the session durations.
We can then construct our zero-mean signal
which will be easier to work with, and which we’ll focus on for the rest of the post. We’ll also only focus on the autocorrelation function Rx(τ), although all the same reasoning applies to cross-correlation functions Rxy(τ) as well.
The direct estimator
Given our one sample X1(t), the unbiased estimator for Rx(τ), which is just the covariance (because we removed the mean) between x(t) and x(t + τ), is given by
which is just the usual covariance estimator computed by summing over the product of all Ni (where Ni = Ti – τ – 1) valid pairs (x(t), x(t+τ)) and dividing by Ni – 1.
This we will refer to as the “direct” method, since it directly applies the usual sample covariance formula. (Note that for multiple samples, one collects all valid pairs (x(t), x(t+τ)) across all samples, and divides by Ntotal – 1, where Ntotal = T1 – τ – 1 + T2 – τ – 1 + … .)
The advantages of the direct method are that (1) it gives an unbiased estimate of Rx(τ), and (2) it’s pretty easy to deal with NaNs, since you can just ignore all the (x(t), x(t+τ)) pairs that include a NaN and decrement Ntotal accordingly. A disadvantage, however, is that it is quite slow, since you have to loop explicitly over all τ.
The standard estimator
A faster method, employed all over signal processing is use the estimator
which estimates the correlation function via the convolution of x(t) and x(-t). We’ll call this the standard estimator. The advantage of the standard estimator is that convolutions can be done via the Fast Fourier Transform (FFT), which makes for a much faster algorithm, especially when we have long time-series or high sampling rates.
The key difference between the direct and the standard estimator is that the latter is normalized by Ti-1, which is not a function of τ. This is how SciPy’s scipy.signal.correlate works, along with MATLAB’s xcorr function with default settings. In fact, by default these algorithms don’t even divide by Ti-1, but instead return an “unscaled” version of the covariance function:
While this is quite fast, as well as quite useful in many applications, the downsides are that (1) it’s hard to deal with NaNs, since this will generally preclude performing a straightforward FFT, and (2) this estimator can introduce a substantial bias, since the normalization is the same for all τ, even though we sum over different numbers of (x(t), x(t+τ)) pairs for different τ.
Unfortunately, the NaN problem is only solved by using the direct method (or via interpolating first, but that’s another story), but we can solve the bias problem quite simply.
The “triangle” estimator
To remove the bias from the standard estimator, we can just divide the result of the standard estimator by a normalization function that does depend on τ, so as to match the direct estimator. In other words, we can use the estimator
which we’ll call the triangle estimator since the normalization Ni(τ) = Ti – |τ| – 1 is a triangular function of τ, and provides an unbiased estimate of Rx(τ) since it correctly accounts for the different number of terms in the sum for different time lags τ.
Therefore, if you want an unbiased correlation function estimate from a sample time-series, use the triangle estimator. (Note: you’ll have to do this yourself in Python, or specify “unbiased” as the “scaleopt” argument of MATLAB’s xcorr).
Why the default estimator is biased
It may seem strange that signal processing packages use a biased estimator by default, when the unbiased one is so easy to compute. So why is the biased one the standard?
First, if your recording time far exceeds the timescales you expect in your signal, it doesn’t really make a difference. For instance, if Xi(t) were a 10 kHz, 100-second recording of a noise-driven RC circuit with a time constant τRC somewhere in the range of 1-10 ms, then we would have that
i.e. the normalization factor in the whole range from 0-100 ms (which should be plenty to estimate a 10 ms time constant) barely changes at all, due to the long recording time. Cases like this are common in signal processing, and so even though the estimator is a bit biased, if your recording time greatly exceeds the timescales you expect in the signal, it really doesn’t make much difference.
Second, and a bit more fundamental, is that the correlation function estimated via the unbiased triangle estimator can end up being an invalid correlation function. In particular, one can end up with an estimate where
for some τ ≠ 0, which breaks the important property that Rx(0) ≥ |Rx(τ)| for all τ. This shouldn’t be too surprising, since when normalizing at τ = 0 we divide by a very large number and when normalizing at very large τ we divide by a much small number, which can drastically amplify small fluctuations in the estimator.
Depending on what you’re trying to do, this may or may not be a problem. Having an invalid correlation function, however, can greatly interfere with prediction or sampling, i.e. you could not use an invalid correlation function to specify a valid random process P[X(t)]. Since these are common use cases in signal processing, often a valid yet biased correlation function estimate is preferred over an unbiased but invalid estimate.
A realistic case where this makes a difference
It follows that the biased estimator really only causes problems when the correlation timescales in the data are on the same order as the sample duration. Now, you might be thinking that if we’re in that regime we have no hope of estimating correlations at those timescales in the first place, since we simply don’t have enough data. While the triangle estimate of Rx(400) from a 500 timestep sample may be unbiased, it will have huge variance, since if the signal really is significantly correlated over 400 timesteps, then the 99 timesteps available to the estimator at τ=400 will be far from i.i.d., so we’ll have too few effective independent samples for anything useful anyway.
While that is perfectly sensible, one case where this matters is when we have a large number of short samples of our data. In fact, this is quite common in biology, e.g. if we have data across many short experimental “trials”, if we’re computing behavioral correlations from video data with frequent occlusion periods, if we’re studying brain activity conditioned on a specific brief behavioral states, etc.
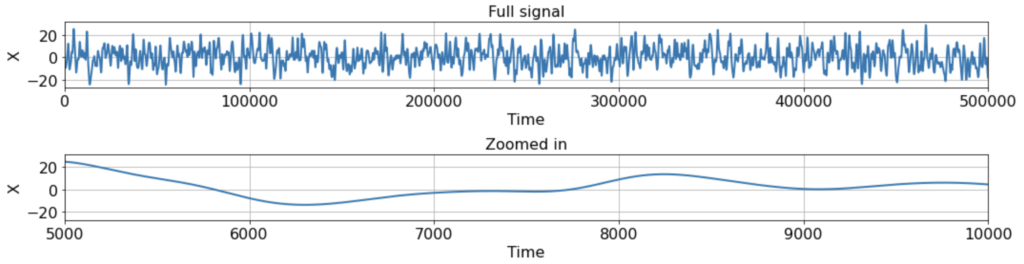
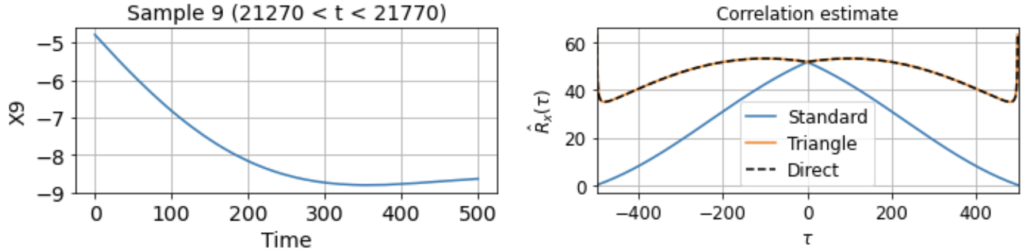
To be concrete, let’s see how this all plays out in the following scenario. Suppose we have a single ground-truth signal X(t) of T = 500K timesteps, with an intrinsic timescale of about 300 timesteps (constructed here by smoothing white noise with a 300-timestep squared exponential filter):
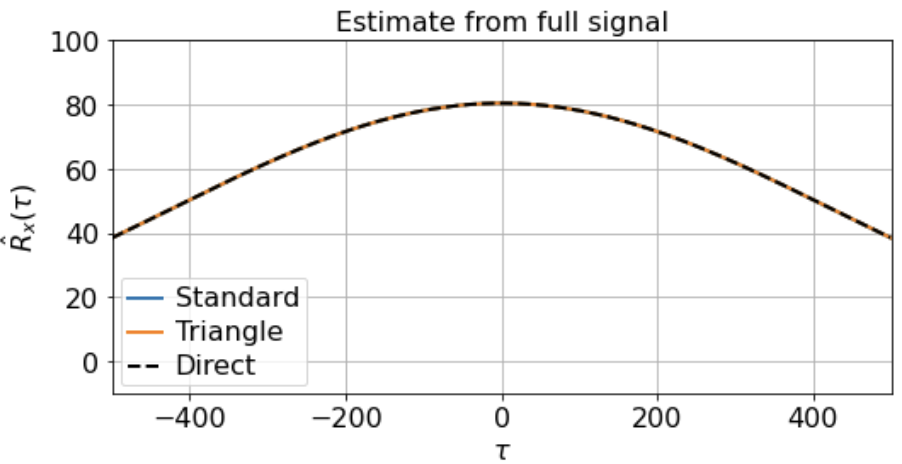
As you can see, the signal is smooth when we zoom in far enough, hence far from i.i.d. close up. Suppose, however, that we’re lucky enough to measure the full signal across all 500K timesteps, and we estimate the correlation function from -500 < τ < 500 using either the direct, standard, or triangle estimators. In this case, the estimator we use does not really matter, as the estimates are extremely similar:
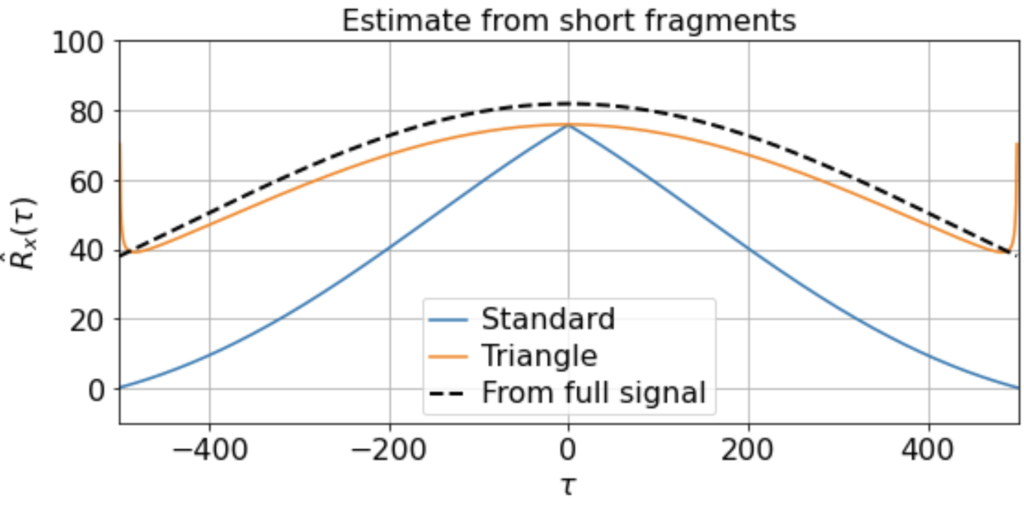
Suppose, however, that we only observe X(t) for 500 timesteps at a time, and that these 500-timestep fragments are randomly distributed throughout the full signal. For instance, maybe we’re interested some slow metabolic process only when the animal is awake, but the animal is only awake for 500 timesteps at a time. Or we’re interested in some state-dependent neural computation, but the state of interest only occurs in about 500-timestep windows.
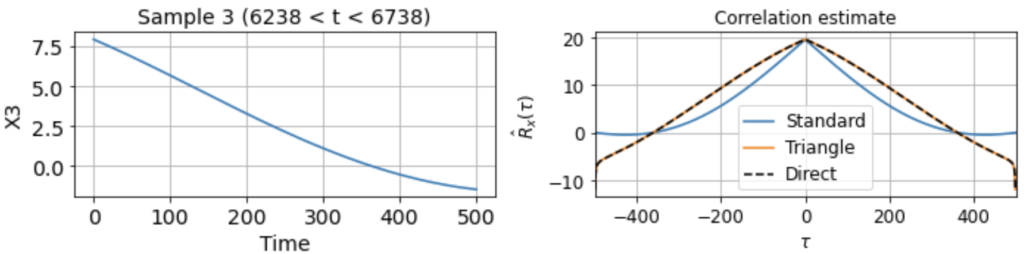
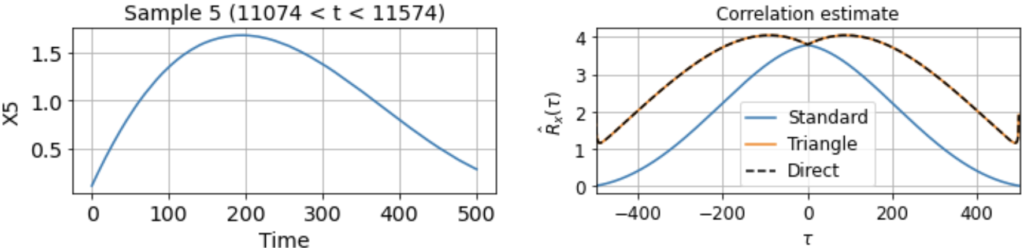
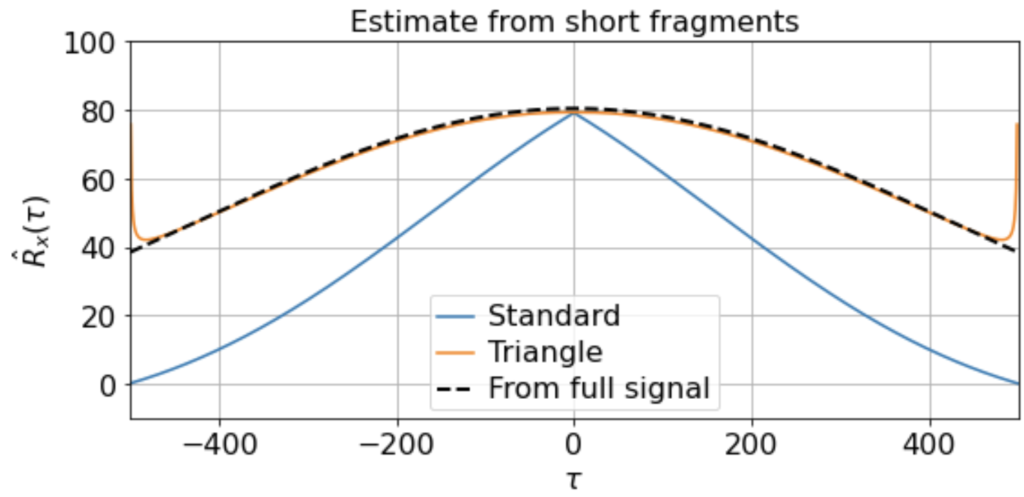
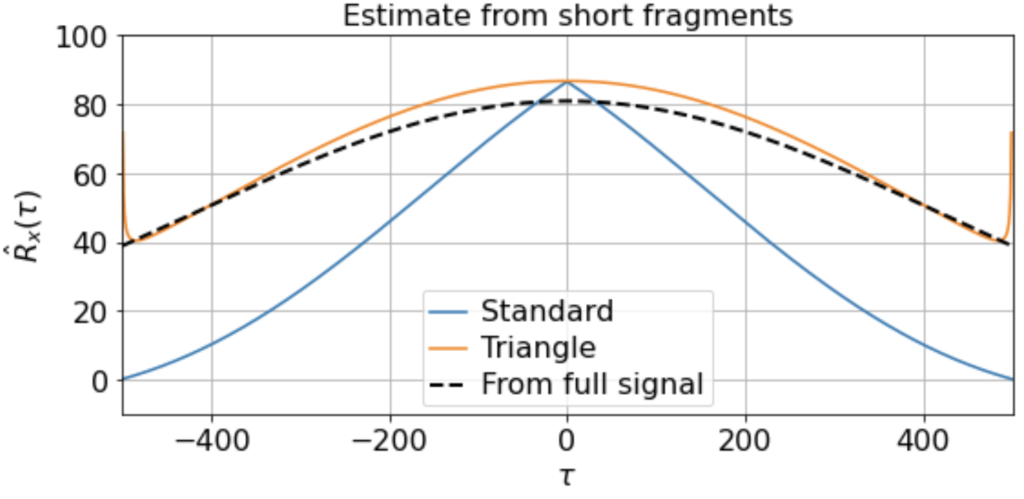
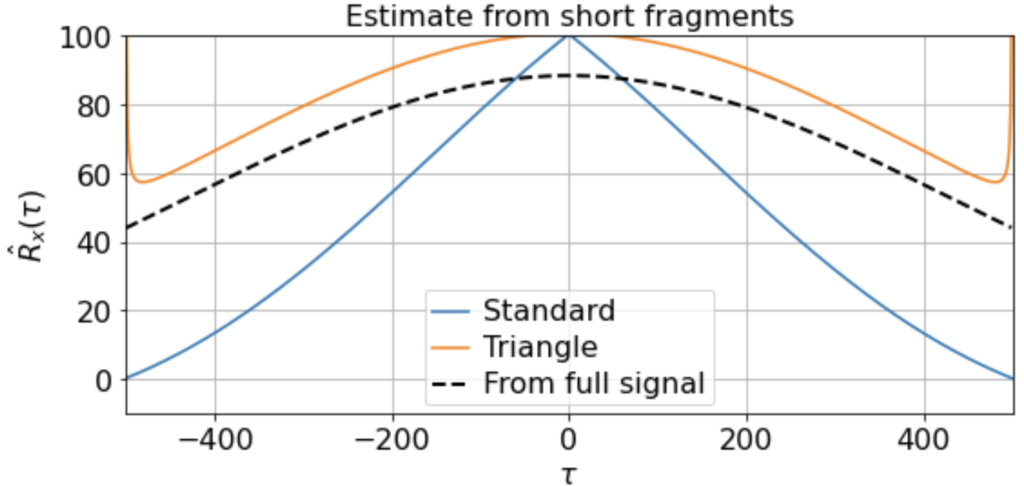
As usual, we first estimate the mean μx across all samples. We then use this to estimate the correlation function Rx(τ) from each 500-timestep sample. Using our three different methods produces something like:
Now we see clearly that the estimates differ rather wildly both across individual samples (since each sample contains only a small, nonrepresentative part of the full signal), as well as between the standard and triangle estimators (and only the triangle estimator matches the direct estimator).
Notably, for τ near 500, the standard estimator estimates Rx(τ) ≈ 0 for all samples, even though we know Rx(500) should be around 40 (see the estimate from full signal above). On the other hand, the standard biased estimator has very low variance around τ near 500, whereas the triangle estimate, while unbiased, is kind of all over the place for Rx(τ ≈ 500). Moreover, we can see in the sample X5 that the estimated correlation function is in fact an invalid correlation function, since Rx(100) > Rx(0). Thus, if you wanted to use an unbiased estimate of the correlation function for sampling purposes, you would run into trouble.
Nonetheless, if we have sufficiently many samples, even if they are of short duration, we can still construct a good estimate by averaging the estimated correlation functions over the samples:
Here we find that the triangle estimator does a much better job at capturing the nonzero slow correlations present in the signal and matches the direct estimate from the full signal much better than does the standard estimator. (Although note that there is still fairly high variance at the edges, since Ni is so small.)
There will be variation, of course, in the averaged triangle estimate across different renditions of this “experiment”. E.g. running it a few times (for 200 x 500-timestep windows taken from a 500K timestep signal) we get
etc. But in all cases the triangle estimator provides a far better match to the correlation function estimated from the full signal, whereas the standard estimator systematically underestimates the slow correlations.
Time-series analysis is a crucial part of science. The life sciences in particular are full of slow proceses, and when analyzing data it is important to understand how the details of your analyses affect your results and interpretations. Overall, I hope that this post has helped clarify how different correlation function estimators operate, and how they can hide or reveal interesting features of your data in different circumstances.
You can view or download the Jupyter notebook accompanying this post here.
TL;DR: Correlated predictors can yield huge instabilities when estimating weights in regression problems. Different regularization methods tame these instabilities in different ways.
Regularization is usually introduced as a solution to overfitting. By penalizing certain parameter combinations it can improve how models generalize to held-out data by discouraging them from fitting every wiggle of the training data. This is especially useful when your data is high-dimensional relative to the total number of data points.
But regularization can serve another crucial purpose: taming instabilities in parameter estimates caused by highly correlated predictors. Highly correlated predictors (often referred to as multicollinearity) are pervasive in data analysis and can cause a lot of trouble, but in my experience how to handle them is less discussed.
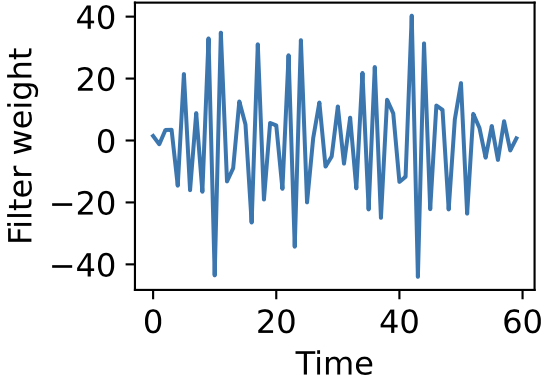
One domain replete with trouble-making predictor correlations is time-series analysis, since signal values at nearby timepoints are often very similar. When estimating the linear filter that best maps one time-series to another, ordinary linear regression often yields something like this:
Strangely, this can occur even when you have many more independent data points than filter weights, so it’s not caused by overfitting. In fact such an estimate may actually predict held-out data pretty well. It’s quite messy and hard to interpret, however, and repeating the fit on different training data can yield wildly different estimates.
Why does this occur? And what can we do about it?
A simple example of correlated predictors yielding unstable weight estimates
Suppose we’re predicting a target variable y from two predictors x1 and x2, whose relationship is
where ηy is noise. We can also write this as
where w = (1, 1)T and x = (x1, x2)T. And suppose that x1 and x2 are not independent but highly correlated, e.g.
where ηx << 1. In other words x2 is twice x1 plus a bit of noise. Maybe we’ve measured two very similar input variables like one audio signal through two microphones, or maybe our automated segmentation of a neural calcium imaging video has split a single neuron into two regions doing basically the same thing.
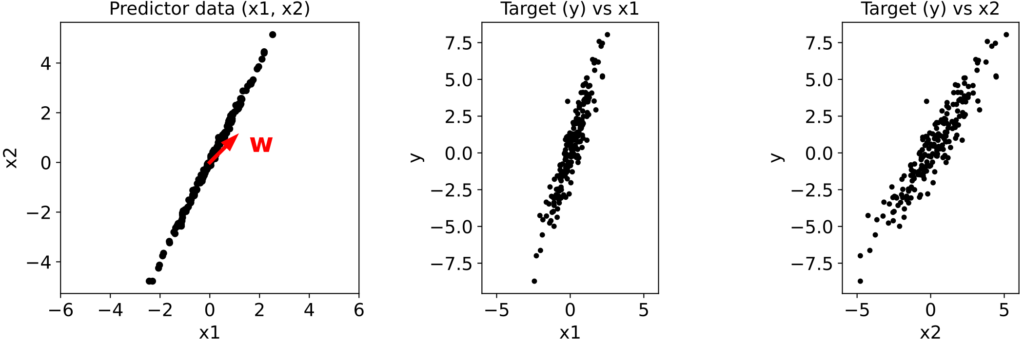
Let’s generate 200 data points and plot x2 vs x1, y vs x1, and y vs x2:
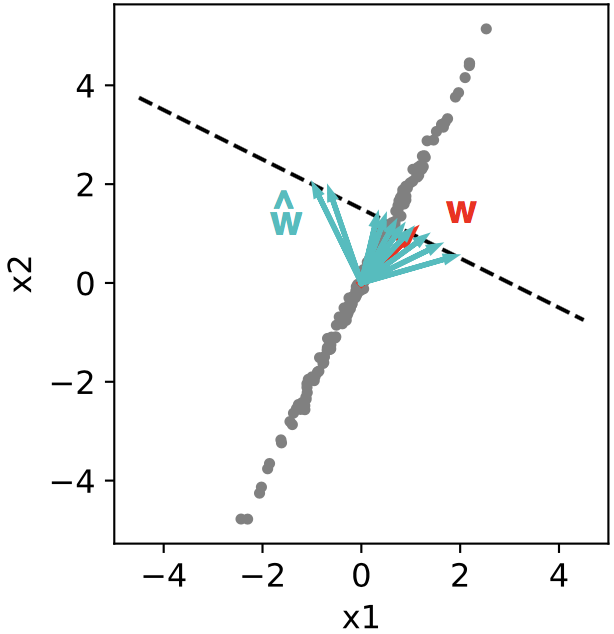
The ground truth weight vector w = (1, 1)T is shown in red.
Estimating the weights via unregularized linear regression
Now, because our two predictors are highly correlated, we have
and so
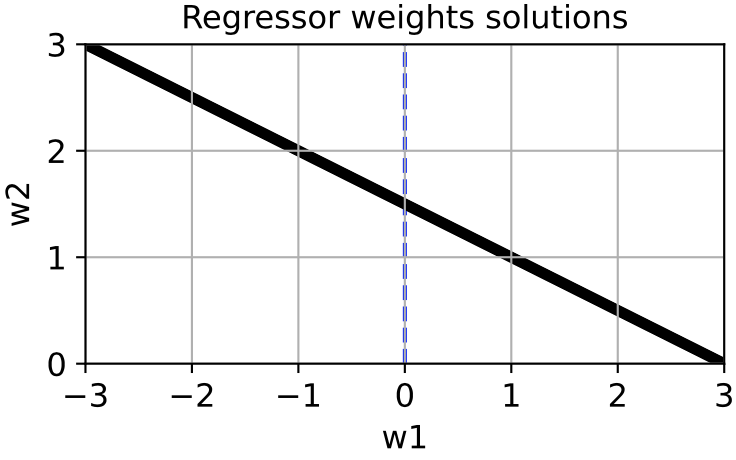
and so on. Thus, effectively there isn’t one best weight estimate, but a whole space of equally good estimates, defined by the line w1 + 2w2 = 3:
Which particular choice of w gets picked out by unregularized linear regression will depend much more on the particular noise instantation ηy than the relationship between x1, x2, and y.
If we use scikit-learn‘s linear_model.LinearRegression to find the best estimate w_hat given different ηy we get a wide range of answers (cyan), all lying on the line w1 + 2w2 = 3:
Importantly, none of these estimates are bad at predicting held-out data. The weight estimator here just has a high variance. If many predictors are involved, e.g. inputs at different lags in a time-series dataset, this can make the recovered weight vectors or filters messy and hard to interpret, even if they generalize quite well.
Modifying the loss function with Ridge (L2) or Lasso (L1) regularization
How do we fix this? Because many different weight estimates may be equally good at predicting held out data, there is not necessarily a single best method. What we can do, however, is understand how different ways of modifying ordinary linear regression affect our estimate of w.
Ordinary, unregularized linear regression minimizes the loss function
where
i.e. it minimizes the squared error between the true targets and the predictions from the inputs given the weights.
One popular regularization method, called Ridge Regression (originally developed, in fact, to address multicollinearity), adds an “L2 penalty” to the loss function:
where α is positive and the L2 norm of a vector is its Euclidean distance from the origin:
This means that the estimator will prefer weight vectors that are closer “as the crow flies” to the origin .
A second regularization method, called Lasso Regression, instead adds an “L1 penalty” to the loss function:
where the L1 norm is
also sometimes called the city-block or Manhattan norm, which is the distance from w to the origin if you can only move vertically and horizontally. Lasso therefore favors w‘s with smaller L1 norm.
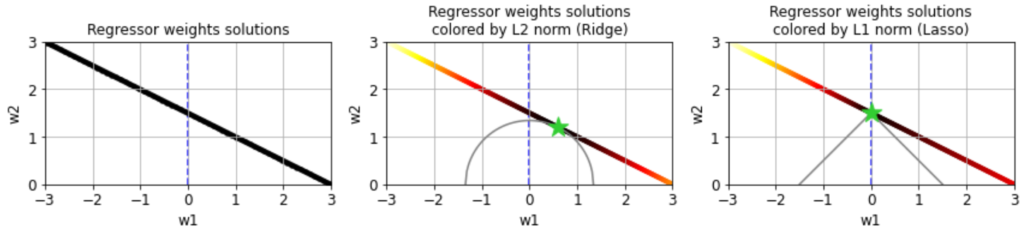
The difference between Ridge and Lasso may seem a bit subtle but yields qualitative differences in the regression results. If we color the solution space for w by their L2 (Ridge) or L1 (Lasso) norm, we can see that the L2 norm is minimized at the intersection (green star) of the solution space for w and the circle around the origin that touches it, whereas the L1 norm is minimized where the diamond around the origin touches the solution space for w.
This is because circles (or spheres in higher dimensions) correspond to sets of weight vectors with constant L2 norm, whereas diamonds correspond to sets of weight vectors with constant L1 norm. The L2 or L1 norm of any w in our solution space is in turn given by the “radius” of the circle or diamond that intersects it. The diamond with radius 1.5, for instance, is the smallest one that intersects this solution space, and therefore the minimum L1 norm of w on this space is 1.5.
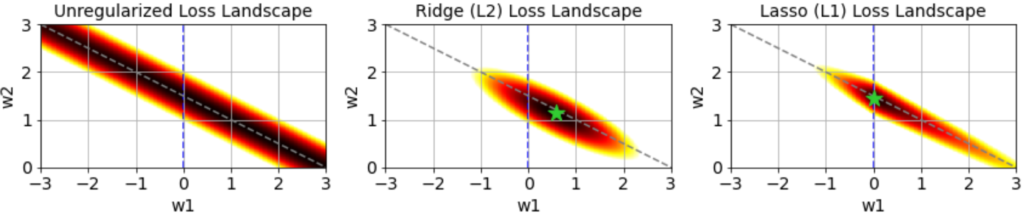
We can also show a larger region of the unregularized, Ridge, or Lasso loss functions using the equations above, where hotter colors represent larger loss and the green star shows the minimum:
The loss landscape for unregularized regression does not have a well defined minimum, which is why weight estimates given different noise instantiations have such high variance. The Ridge and Lasso losses, however, are minimized at a single point, which will dramatically reduce this variance.
The locations of the Ridge and Lasso minima are important. Notably, the “pointiness” of the L1 diamond means the minimum L1 norm of some solution space will usually be on a subset of the coordinate axes of the complete space of w. This is why Lasso Regression is said to “sparsify” the weight estimate, usually assigning a nonzero weight to only one of several highly correlated predictors, and is why you’ll frequently here “L1” and “sparsity” come up together in data analysis. Ridge Regression, on the other hand, yields a minimum that “balances” the weights assigned to correlated predictors: predictors with similar variance and predictive power get assigned similar weights. In time-series analysis this is why Ridge Regression tends to find smoother filters, since nearby input timepoints are often very similar in variance and predictive power of the output.
Regularizing the weight estimator for our toy dataset
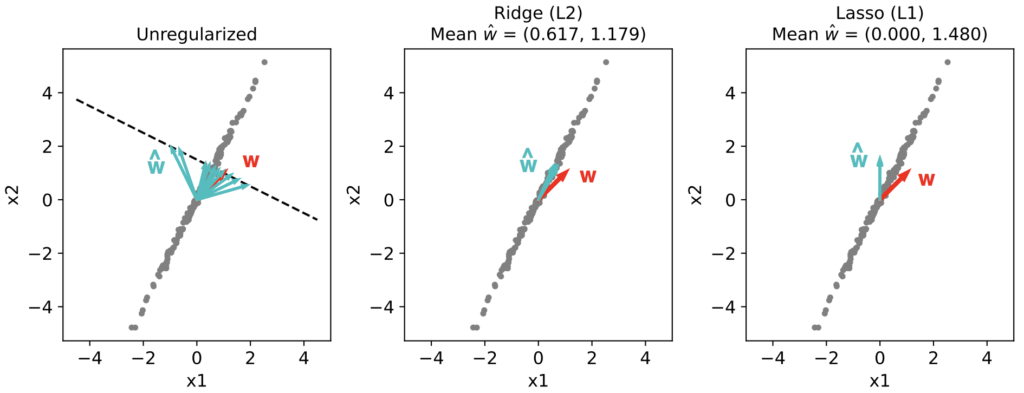
Let’s estimate w for our toy dataset using scikit-learn’s linear_model.Ridge or linear_model.Lasso methods, for several noise instantiations:
As we can see, the variance of the Ridge and Lasso estimators drops almost to zero. The Ridge estimate points along the long axis of the input distribution, “balancing” the weights in accordance with their variance and predictive capacity. Lasso, on the other hand, assigns a nonzero weight only to x2, “sparsifying” the weight estimate as we predicted from the arguments above. For a larger number of predictors Lasso will usually assign nonzero weights to only a subset of the predictors.
Notice, however, that neither estimate corresponds to the true w used to generate the data. Really, there isn’t a (unique) ground truth solution here, since all w‘s along the line w1 + 2w2 = 3 are effectively equal. Different regularizers simply yield different estimates.
When using Ridge or Lasso we have to choose a value for α, which we can’t necessarily do via cross-validation, since many solutions may be equally good at predicting held out data. Practically, there will often be a wide range of αthat yield similar results, but ultimately the choice of α is up to you, based on what you want your final weights to look like. Note that the larger the value of α, the farther the final weight estimate will lie from the unregularized solution space, since the optimization will more significantly trade off predictability of the target for smaller L2 or L1 norms of the weight vector.
Ridge and Lasso regularization can be applied to much more than just linear regression, simply by adding their corresponding terms to the relevant loss function. Once again, they can be relevant even outside the overfitting regime of high-dimensional but weakly sampled data.
A time-series example
Here’s a more interesting application: estimating the linear filter that best maps one time-series to another, a common problem in neuroscience and many other fields.
First, let our input x(t) be a pure white-noise process, and we’ll create an example output y(t) by passing the input through a known linear filter h(t) and adding a bit more noise:
We then attempt to recover h(t) using linear regression.
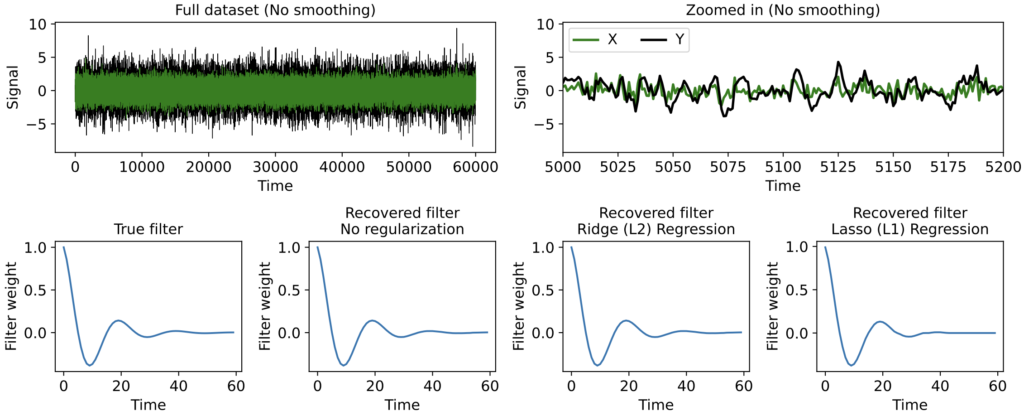
When the input is perfectly white, we don’t need any regularization to recover the true filter. This is because input signals at neighboring times are completely uncorrelated, so multicollinearity is not an issue.
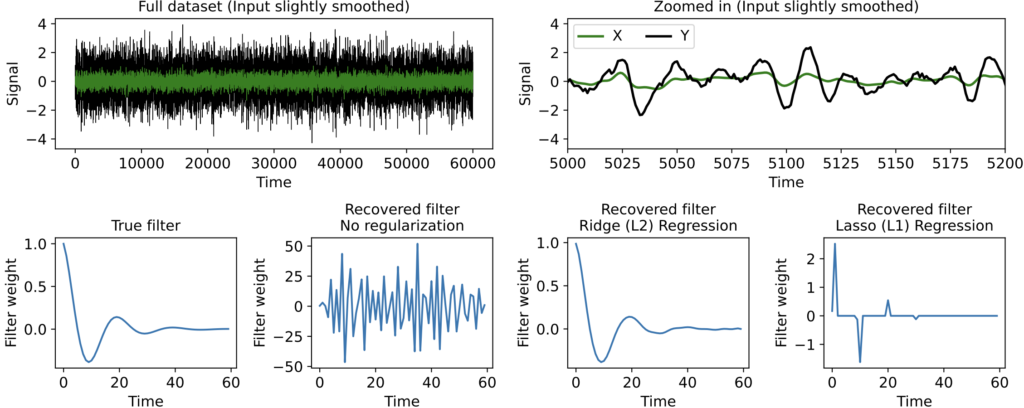
But now suppose the input signal x(t) has been smoothed a bit (here convolved with a squared exponential kernel only 3 timesteps wide) before being filtered to produce the output y(t). This introduces correlations between x(t) at nearby timepoints, reflecting a common phenomenon when datasets comprise measured rather than computer-generated signals. Now regularization makes a huge difference.
As we can see, when no regularization is used the filter estimate is extremely messy. This occurs even though we have far more timepoints than filter parameters, so the messiness is not an overfitting issue — it is instead caused by correlations in the input signal x(t). When we use Ridge or Lasso we get a much more interpretable estimate, with Lasso producing a clearly sparse filter.
Note again, though, that even though Ridge Regression gives a more accurate filter estimate in this particular example, there is rarely an objectively “best” regularization to use (nor will cross-validation be much help in deciding, since often many different filters predict held-out data equally well). Ultimately, which regularization method you use depends on what kind of structure you want to impose on the filter estimate. Ridge, for instance, tends to yield smoother filters in time-series data, whereas Lasso tends to find the best small set of time lags of the input needed to predict the output.
Other methods for handling multicollinearity
Ridge and Lasso Regression are not the only ways to deal with multicollinearity. Other methods include:
Basis functions: A common technique in time-series analysis is to represent filters as a weighted sum of a small number of basis functions. This reduces the number of weights to find and can be very useful, especially if projections of the inputs onto the different basis functions are not strongly correlated. However, be careful when making claims about how the filter shape reflects relationships among signals in your dataset, since the shape of the final filter estimate will be strongly influenced by your choice of basis functions.
Taking Fourier transforms: Convolution in the time domain is multiplication in the frequency domain. To find a linear filter you can thus Fourier transform your output and input time-series, take their quotient, and convert back to the time domain. However, this does not necessarily generalize well to problems with strong nonlinearities or where the output depends on multiple input time-series.
Elastic net regularization: Elastic net regularization lies in between Ridge and Lasso, penalizing the squared error loss function via a weighted sum of the L2 and L1 norms.
Principle component regression: You could also first apply principal component analysis (PCA) to your predictors and only keep the top principal components, which will be uncorrelated by construction, then predict the target using those. In our toy example, this would mean first studying the distribution of x1, x2 and deciding to replace the pair with only a single variable x*, and then finding the single weight that maps x* to y.
Averaging over trials: Another method is to perform unregularized linear regression on many trials or subsets of your training data, then average the resulting weight vectors. This can sometimes clean up otherwise messy weight estimates, but since multicollinearity yields weight estimates with such high variance, it can require a large number of trials.
Remember, whatever dataset you have, there may not be a best way to handle multicollinearity, as many options may be equally good when it comes to predicting held out data. The most important thing you can do is to understand how your analysis affects the structure of your results. In fact, this is true not just when handling correlated predictors, but essentially everywhere in the world of data analysis.
You can view or download the Jupyter notebook accompanying this post here.
![\[ H[P] = - \sum_{i=1}^N p_i \log p_i \quad \quad (1) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-932f4df0d7fefa98158b85a4a6b9b7d1_l3.png "Rendered by QuickLaTeX.com")
![\[ H[P] = - \sum_{i=1}^N \frac{1}{N} \log \frac{1}{N} = - \log \frac{1}{N} = \log N. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-8fe33bf846774d7b450a9952d821b9a9_l3.png "Rendered by QuickLaTeX.com")
![\[ N_{seq}(L) = {L \choose L_1} {L - L_1 \choose L_2} \cdots {L - L_1 - \cdots - L_{N-1} \choose L_N} \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-91e5dd8a7d66e5e86504cdde6fe5ac7a_l3.png "Rendered by QuickLaTeX.com")
![\[ = \frac{L!}{L_1! (L-L_1)!} \times \frac{(L-L_1)!}{L_2! (L-L_1-L_2)!} \cdots = \frac{L!}{L_1! L_2! \cdots L_N!} \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-2a078b193fa7737b47984865dcf90df7_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) = \log \left( \frac{L!}{L_1! \cdots L_N!} \right) = \log L! - \log L_1! - \dots - \log L_N!, \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-33b5f17fe4cdd061fdc5704ccaaa4719_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) \approx L \log L - L - (L_1 \log L_1 - L_1) - \dots - (L_N \log L_N - L_N). \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-991c0866714b257c513cd88405598b32_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) \approx L \log L - (L_1 \log L_1 + \dots + L_N \log L_N) - L + (L_1 + \dots + L_N) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-33892d2c560a13d04fa4110528f43436_l3.png "Rendered by QuickLaTeX.com")
![\[ = L \log L - (L_1 \log L_1 + \dots + L_N \log L_N) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a88ced4d8eb297d48b780b3fc488ca91_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) \approx L\left[ \log L - \left(\frac{L_1}{L} \log L_1 + \dots + \frac{L_N}{L} \log L_N \right) \right]. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-7ffe047d2e0bde5aff1a95f8dd1388ca_l3.png "Rendered by QuickLaTeX.com")
![\[ = L\left[ \log L - (\hat{p}_1 \log L + \dots + \hat{p}_N \log L) - (\hat{p}_1 \log \hat{p}_1 + \cdots + \hat{p}_N \log \hat{p}_N) \right] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-37d2f5ba33bb540acf1dcbee746cf9ed_l3.png "Rendered by QuickLaTeX.com")
![\[ = L\left[ \log L - \log L - (\hat{p}_1 \log \hat{p}_1 + \cdots + \hat{p}_N \log \hat{p}_N) \right] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-30f6fa71d0b6f887ca89574fe9437966_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{p}_i \equiv L_i/L \quad \text{and} \quad \sum_i \hat{p}_i = 1 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-7f71cbcb863110c1e6e51877f335f6e7_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) \approx L\left[ -(\hat{p}_1 \log \hat{p}_1 + \cdots + \hat{p}_N \log \hat{p}_N) \right] = -L \sum_i \hat{p}_i \log \hat{p}_i. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-1cabd4a04738bb2f7b88c505b771d402_l3.png "Rendered by QuickLaTeX.com")
![\[ \log N_{seq}(L) \to -L\sum_i p_i \log p_i . \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-104073d8b692a3647ab867b1bf965700_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{\log N_{seq}(L)}{L} \to -\sum_i p_i \log p_i = H[P]. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-366a3cff1ef32ef47646f78c4a9e3017_l3.png "Rendered by QuickLaTeX.com")
![\[ R_x(\tau) \equiv \textrm{E}[X(t)X(t+\tau)] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-b9c20aae7148198671eb0eaa5c905f2a_l3.png "Rendered by QuickLaTeX.com")
![\[ C_x(\tau) \equiv \textrm{E}[(X(t) - \mu_x)(X(t+\tau) - \mu_x)] = R_x(\tau) - \mu_x^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-854088825739a14aaa12b6ca97d431df_l3.png "Rendered by QuickLaTeX.com")
![\[ R_{xy}(\tau) \equiv \textrm{E}[X(t)Y(t+\tau)] \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-8854bb25f280c1d3f0a9bb9c3557a1e4_l3.png "Rendered by QuickLaTeX.com")
![\[ C_{xy}(\tau) \equiv \textrm{E}[(X(t) -\mu_x)(Y(t+\tau) - \mu_y)] = R_{xy}(\tau) - \mu_x\mu_y. \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-df7f7f565541ad111429b098494ea277_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{\mu}_x = \frac{1}{T_1} \sum_{t=1}^{T_1} x_1^*(t). \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-290e38dfd0b97929fa9a3e0f0708b5b6_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{\mu}_x = \frac{1}{\sum_i T_i} \sum_{i=1}^m \sum_{t = 1}^{T_i} x_i^*(t) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-050a089881ef27f1a99cdd25b59a4205_l3.png "Rendered by QuickLaTeX.com")
![\[ X_i(t) = X_i^*(t) - \hat{\mu}_x \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-6d3d78f7321c7b8c54ea8164065b02da_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{R}_x(\tau) = \frac{1}{N_i-1} \sum_{t=1}^{N_i} x_i(t)x_i(t+\tau) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c835d6d73c33fc8279e4907298df417e_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{R}_x^{st}(\tau) = \frac{1}{T_i - 1} \sum_{t=1}^{T_i-\tau} x_i(t)x_i(t+\tau) = \frac{1}{T_i - 1} x(t) \ast x(-t) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-9acd1286a7b2c5702286b26eabcc6703_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{R}_x^{st}(\tau) = \sum_{t=1}^{T_i-\tau} x_i(t)x_i(t+\tau) = x(t) \ast x(-t). \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-09b2c3a5c669cfcc9e268d1cf1a2beca_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{R}_x^{tri}(\tau) = \frac{\hat{R}_x^{st}(\tau)}{T_i - |\tau| - 1} = \frac{x(t) \ast x(-t)}{T_i - |\tau| - 1} . \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-244968c3ea578d42a2612e6fa427958b_l3.png "Rendered by QuickLaTeX.com")
![\[ \frac{N_i(0 ms)}{N_i(100 ms)} = \frac{100 s - 0 ms - .1 ms}{100 s - 10 ms - .1 ms} = \frac{99.999 s}{99.989 s} \approx 1 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-6f65be06e0949233e462baaef3c130f7_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{R}_x^{tri}(0) < \hat{R}_x^{tri}(\tau) \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c3daee16ecf2e8b1fcaff52c53dc266d_l3.png "Rendered by QuickLaTeX.com")
![\[y = x_1 + x_2 + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-01021efc85e98e3ba6e8e1f8a70e5c37_l3.png "Rendered by QuickLaTeX.com")
![\[y = \mathbf{w}^T \mathbf{x} + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-25791c89d13bd4eb75220f15e8863014_l3.png "Rendered by QuickLaTeX.com")
![\[ x_2 = 2x_1 + \eta_x \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-b650927121fc4a99cb88303ecfedf6f8_l3.png "Rendered by QuickLaTeX.com")
![\[ x_2 \approx 2x_1, \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-5acdb351cf550d1c6402914256e32cae_l3.png "Rendered by QuickLaTeX.com")
![\[ y = x_1 + x_2 + \eta_y \approx 3x_1 + \eta_y \approx 1.5x_2 + \eta_y \approx 5x_1 - x_2 + \eta_y\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-ace735983164449edd48dd09e0535072_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a62adc9c3a168552e61a4144b5910918_l3.png "Rendered by QuickLaTeX.com")
![\[ \hat{y}_i = w_1x_1 + w_2x_2 + ... \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a63e0626ed94149ee89784b11a66ec91_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 + \alpha \lVert \mathbf{w} \rVert_2^2 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-a689eb87a603c782d504e0b361a4ad1e_l3.png "Rendered by QuickLaTeX.com")
![\[\lVert \mathbf{w} \rVert_2 = \sqrt{w_1^2 + w_2^2 + w_3^2 + ...} .\]](https://rkp.science/wp-content/ql-cache/quicklatex.com-05731c7d203f3f4c69989828204b5ad7_l3.png "Rendered by QuickLaTeX.com")
![\[\mathcal{L}(\mathbf{w}) = \frac{1}{N}\sum_{i = 1}^N (y_i - \hat{y}_i)^2 + \alpha \lVert \mathbf{w} \rVert_1 \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-2412607b301febdfccd17399102fa49b_l3.png "Rendered by QuickLaTeX.com")
![\[ \lVert \mathbf{w} \rVert_1 = |w_1| + |w_2| + ... \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-c92d458a9879a5865eef8ac2bf8a4d58_l3.png "Rendered by QuickLaTeX.com")
![\[ y(t) = x(t) \ast h(t) + \eta_y(t) . \]](https://rkp.science/wp-content/ql-cache/quicklatex.com-f174eb7f3e420efdd764cb4968df720e_l3.png "Rendered by QuickLaTeX.com")